Last Updated
November 19, 2025
Table of Contents
Share
Authors

Murtaza

The internet doesn’t break often. But when it does, the world suddenly sees how much of modern digital life depends on a small number of invisible infrastructure players. That’s exactly what happened on November 18, 2025, when Cloudflare - one of the world’s biggest edge and security networks - experienced a major disruption that rippled across the global web.
AI platforms were among the hardest hit. Users trying to access ChatGPT, Perplexity, and other LLM interfaces reported endless loading, 500-errors, or Cloudflare challenge failures. And while the models themselves were healthy, most requests simply never made it far enough to reach them.
For generative-AI companies, this outage was more than an inconvenience. It was a clear reminder that great AI experiences aren’t powered by models alone. They rely on a dependable, resilient infrastructure stack. And if the first layer collapses, everything above it becomes unreachable.
This article breaks down the incident, why LLM-based platforms were disproportionately affected, what the timeline looked like, and - most importantly - what resilience lessons AI companies must learn.
All information is based on verified public reports from AP News, Reuters, The Guardian, and other reputable sources.
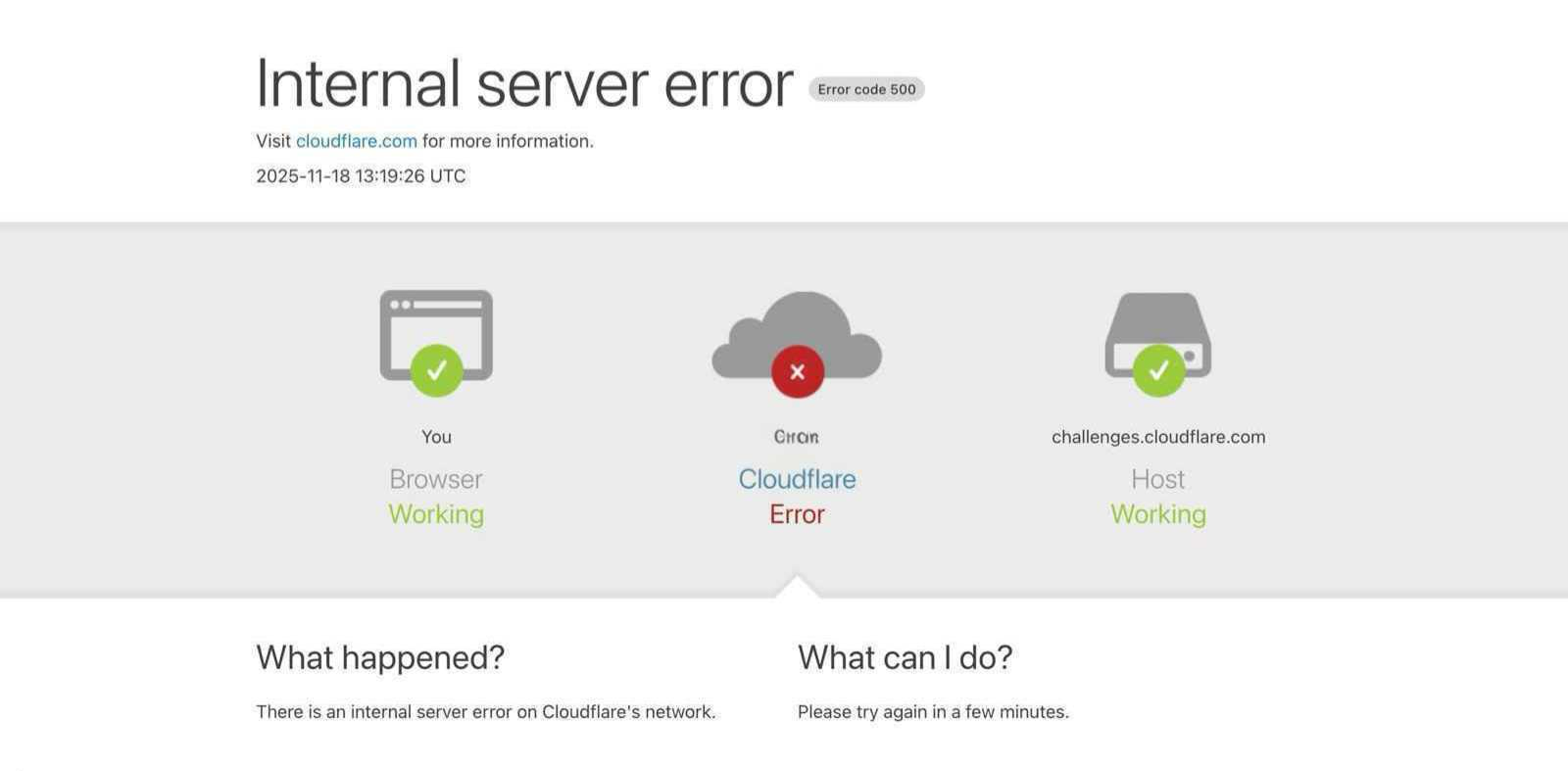
Cloudflare publicly confirmed that the disruption stemmed from “a spike in unusual traffic” starting around 11:20 AM UTC, which created widespread routing instability and triggered internal server errors across customer-facing sites.
This was reported by multiple outlets including The Guardian, which highlighted Cloudflare’s explanation of anomalous traffic levels causing the disruption.
To understand the technical nature of the issue:
This wasn’t a single-application problem. It was a systemic edge-level breakdown - and that matters a lot when your product relies on low-latency API calls, real-time streaming, or AI inference.
Although the outage hit many high-traffic services, AI platforms experienced visible and immediate failures. Users attempting to access ChatGPT shared screenshots of “Please unblock challenges.cloudflare.com” errors, as reported by Reddit users on r/ChatGPT.
The reason AI services suffered more than content or e-commerce platforms comes down to unique architectural characteristics.
Here are the core factors:
AI applications require every user prompt to reach the backend API. Unlike static websites, nothing meaningful can be cached at the edge.
If the edge collapses, every request fails instantly.
LLMs generate dynamic answers. They cannot rely on CDN caching the way a blog page or an image file can.
This means AI services have almost zero fallback capacity during a CDN or edge outage.
AI platforms use Cloudflare for:
When these services fail, requests are dropped before reaching the model.

Many AI teams rely exclusively on a single edge provider.
This creates an infrastructure bottleneck: if the ingress fails, the entire AI system becomes unreachable - even when model servers remain completely healthy.
Typical AI observability stacks monitor inference latency, token throughput, GPU load, and origin API health.
Edge failures often do not appear in these dashboards, creating a confusing situation where everything internally looks healthy while the user experience is broken.
Together, these factors explain why AI apps were among the first and most visible victims of the Cloudflare outage.
Based on consolidated reports from The Guardian, AP News, Reuters, and Cloudflare communications, here is the clearest timeline available:
This timeline highlights how rapidly the disruption unfolded and how long the tail of the outage lasted.
The disruption caused ripple effects across industries. For generative-AI companies - especially those with customer-facing products - the implications are significant.
Here are the most important lessons.
When AI tools stop responding, people get frustrated instantly because AI interactions are conversational and expectation-driven.
Inconsistency damages brand reliability and retention.
Enterprise clients expect uptime guarantees.
If your AI tool goes down because your edge provider failed, you still risk SLA penalties unless your contract specifically excludes third-party outages.
Outages force engineering and product teams into immediate escalation mode - investigating logs, validating internal systems, and responding to customer queries - all while the root cause lies outside their control.
Resilience becomes a selling point.
AI providers who architect for failure earn trust faster than those relying on a single provider.
A single point of failure at the edge can undermine millions of dollars of investment in LLM infrastructure, GPUs, R&D, and customer onboarding.
In short: AI companies cannot treat edge providers as invisible. They must treat them as critical dependencies requiring redundancy.
Consultadd recommends a structured, multi-layer resilience strategy. Each point below includes both the summary and a deeper explanation for practitioners.
This ensures that a single provider's failure does not block user prompts.
Users should never see a dead interface.
This prevents overload during partial outages and maximizes successful request delivery.
This gives teams early warning before users even notice issues.
Your status domain must survive even if your primary edge provider is down.
Having a separate DNS path and CDN ensures communication continuity.
Periodically simulate a CDN-level outage to test:
This is how platforms become battle-tested.
Every disruption requires a documented review so architectural changes are implemented, not postponed.
Consultadd specializes in building next-generation generative-AI products - but equally important, we engineer the infrastructure foundation that makes them dependable.
Our expertise includes:
For companies that want AI systems that perform reliably at scale, resilience isn’t optional - it’s a competitive advantage.
The November 2025 Cloudflare outage exposed an uncomfortable truth: the AI revolution is only as strong as the infrastructure it stands on.
Models may be powerful, GPU clusters may be fast, and user bases may scale rapidly - but a failure in the first mile of traffic routing can render an entire AI platform inaccessible.
For generative-AI companies, resilience is now an essential part of the product strategy.
Consultadd helps organizations build AI ecosystems that remain reliable even when the internet’s foundations shake. If your team is planning to scale an AI product or strengthen your infrastructure resilience, we’re here to help.
1. Was this outage caused by a cyberattack?
Cloudflare has not confirmed any malicious activity. The Guardian reported that the company attributed the incident to a sudden spike in unusual traffic patterns, not an attack.
2. Why were AI platforms hit harder than regular websites?
Because LLM requests cannot be cached, validated, or partially served during outages.
Every prompt requires full, live routing.
3. Were ChatGPT or Perplexity themselves down internally?
No. According to public data and user reports, the model infrastructure remained healthy.
Requests simply couldn’t reach the origin because the edge layer was failing.
4. Can AI companies fully prevent this sort of outage?
Not completely. But they can significantly reduce impact through multi-edge routing, redundancy, observability, and proper failover design.
5. What’s the cost of multi-CDN architecture?
Higher than relying on a single provider, but dramatically lower than the cost of customer churn, SLA penalties, or brand damage during outages.
6. How soon should companies invest in resilience?
Immediately. The longer businesses wait, the more technical debt accumulates - and the higher the consequences when an outage strikes.